In my recent project, I explored the intersection of data visualization and sentiment analysis by creating dynamic word clouds. This project allowed me to harness new techniques in Python and develop a fresh approach to visualizing text data. Here’s an overview of the project and the skills I gained.
Project Overview
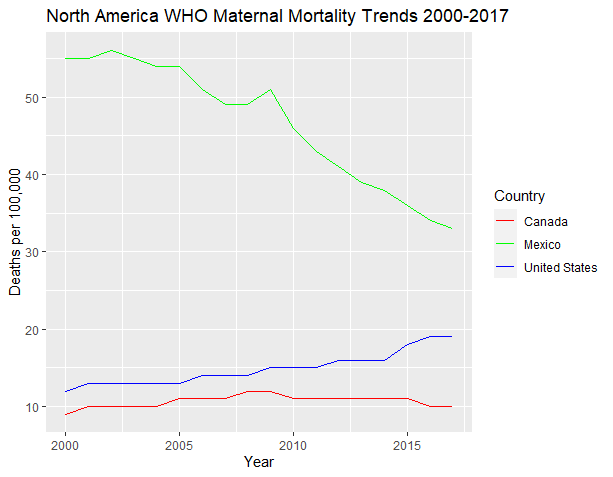
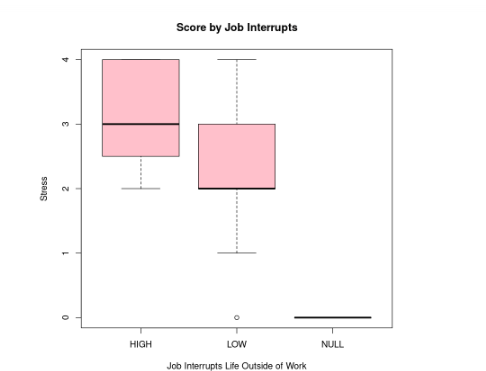
The goal of this project was to enhance data visualization capabilities and apply sentiment analysis to textual data. By creating word clouds, I aimed to visually represent the frequency and significance of words, making it easier to identify key themes and emotions within the text.
Skills and Techniques
- Sentiment Analysis in Python
- I used Python libraries such as
NLTK(Natural Language Toolkit) andTextBlobfor sentiment analysis. These tools enabled me to analyze the sentiment of text data, categorizing it into positive, negative, or neutral sentiments. This analysis was crucial for understanding the emotional tone of the content and provided valuable insights into how different words and phrases contribute to the overall sentiment.
- I used Python libraries such as
- Creating Word Clouds
- I utilized the
WordCloudlibrary in Python to generate visually appealing word clouds. This involved preprocessing text data to remove common stopwords and punctuation, ensuring that the word clouds accurately reflected the most relevant terms. I experimented with various shapes, colors, and fonts to enhance the visual impact and align with the project’s objectives.
- I utilized the
- New Styles of Data Visualization
- The project pushed the boundaries of traditional data visualization by incorporating creative design elements into the word clouds. I explored different styles and formats to represent text data in a way that was both informative and engaging. This approach allowed me to present data in a more visually dynamic manner, making it easier to convey complex information at a glance.
- Code and Implementation
- Here is a brief overview of the code used in this project:
# Start with loading all necessary libraries
import numpy as np
import pandas as pd
from os import path
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
from nltk.tokenize import word_tokenize
# Creating the diary input function to create a diary dictionary
def collect_entries():
entries = []
while True:
date = input("Enter the date (YYYY-MM-DD) or type 'done' to finish: ")
if date.lower() == 'done':
break
entry = input("Enter the diary entry: ")
entries.append({"date": date, "entry": entry})
return entries
diary_data = collect_entries()
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
#create empty string
text = ''
#concatenating entries to empty string for wordcloud
for entry in diary_data:
text += entry["entry"] + " "
wordcloud = WordCloud(background_color="white").generate(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()Outcomes and Reflections
This project demonstrated the power of combining sentiment analysis with creative data visualization techniques. By generating word clouds and analyzing sentiment, I was able to provide a comprehensive view of the textual data. The visual representations not only highlighted key themes but also offered insights into the emotional tone of the content.
The skills gained from this project include advanced text processing, sentiment analysis, and innovative data visualization techniques. These skills are essential for effectively communicating insights and enhancing data-driven decision-making.
Looking Ahead
I’m excited to continue exploring new ways to visualize data and analyze text. This project has opened up possibilities for applying these techniques to various contexts, from business analytics to academic research. If you have any questions or would like to discuss this project further, please feel free to reach out.